OPERATING SYSTEM

An operating system is a program that controls the execution of application programs and acts as an interface between the user of a computer and the computer hardware. In other words, "The software that controls the hardware".
Examples: UNIX, LINUX, Windows, MacOS, iOS, MS-DOS.
An operating system is a program that controls the execution of application programs and acts as an interface between the user of a computer and the computer hardware. In other words, "The software that controls the hardware".
An Operating System is a program that acts as an intermediary between a user of a computer and the computer hardware.
Operating system goals:
– Execute user program.
– Make solving user problems easier. Make the computer
system convenient to use.
– Use the computer hardware in an efficient manner

Objectives of Operating Systems
Operating systems generally have following three major goals:
** To hide details of hardware by creating abstraction. An abstraction is software that hides lower level details and provides a set of higher-level functions. There are several reasons for abstraction.
First, the code needed to control peripheral devices is not standardized. Operating systems provide subroutines called device drivers that perform operations on behalf of programs for example, input/output operations.
Second, the operating system introduces new functions as it abstracts the hardware. For instance, operating system introduces the file abstraction so that programs do not have to deal with disks.
Third, the operating system transforms the computer hardware into multiple virtual computers, each belonging to a different program. Each program that is running is called a process. Each process views the hardware through the lens of abstraction.
Fourth, the operating system can enforce security through abstraction.
** To allocate resources to processes (Manage resources). An operating system controls how processes (the active agents) may access resources (passive entities).
** Provide a pleasant and effective user interface. The user interacts with the operating systems through the user interface and usually interested in the “look and feel” of the operating system. The most important components of the user interface are the command interpreter, the file system, on-line help, and application integration.
Functions of Operating System:
· implementing the user interface
· sharing hardware among users
· allowing users to share data among themselves
· preventing users from interfering with one another
· scheduling resources among users
· facilitating input/output
· recovering from errors
· accounting for resource usage
· facilitating parallel operations
· organizing data for secure and rapid access
· handling network communications.
Operating System Services:
Following are the five services provided by an operating systems to the convenience of the users.
Program Execution
The purpose of a computer systems is to allow the user to execute programs. So the operating systems provides an environment where the user can conveniently run programs. The user does not have to worry about the memory allocation or multitasking or anything. These things are taken care of by the operating systems.
I/O Operations
Each program requires an input and produces output. This involves the use of I/O. The operating systems hides the user the details of underlying hardware for the I/O. All the user sees is that the I/O has been performed without any details. So the operating systems by providing I/O makes it convenient for the users to run programs.File System Manipulation
The output of a program may need to be written into new files or input taken from some files. The operating systems provides this service. The user does not have to worry about secondary storage management. User gives a command for reading or writing to a file and sees his her task accomplished. Thus operating systems makes it easier for user programs to accomplished their task.Communications
There are instances where processes need to communicate with each other to exchange information. It may be between processes running on the same computer or running on the different computers. By providing this service the operating system relieves the user of the worry of passing messages between processes. In case where the messages need to be passed to processes on the other computers through a network it can be done by the user programs.Error Detection
An error is one part of the system may cause malfunctioning of the complete system. To avoid such a situation the operating system constantly monitors the system for detecting the errors. This relieves the user of the worry of errors propagating to various part of the system and causing malfunctioning.System Components
Operating Systems support the following types of system components.
- Process Management
- Main-Memory Management
- File Management
- I/O System Management
- Secondary-Storage Management
- Networking
- Protection System
- Command Interpreter System
Process Management:
The operating system manages many kinds of activities ranging from user programs to system programs like printer spooler, name servers, file server etc. Each of these activities is encapsulated in a process. A process includes the complete execution context (code, data, PC, registers, OS resources in use etc.).
It is important to note that a process is not a program. A process is only ONE instant of a program in execution. There are many processes can be running the same program. The five major activities of an operating system in regard to process management are
- Creation and deletion of user and system processes.
- Suspension and resumption of processes.
- A mechanism for process synchronization.
- A mechanism for process communication.
- A mechanism for deadlock handling.
Main-Memory Management
Primary-Memory or Main-Memory is a large array of words or bytes. Each word or byte has its own address. Main-memory provides storage that can be access directly by the CPU. That is to say for a program to be executed, it must in the main memory.
The major activities of an operating in regard to memory-management are:
- Keep track of which part of memory are currently being used and by whom.
- Decide which process are loaded into memory when memory space becomes available.
- Allocate and deallocate memory space as needed.
File Management
A file is a collected of related information defined by its creator. Computer can store files on the disk (secondary storage), which provide long term storage. Some examples of storage media are magnetic tape, magnetic disk and optical disk. Each of these media has its own properties like speed, capacity, data transfer rate and access methods.
A file systems normally organized into directories to ease their use. These directories may contain files and other directions.
The five main major activities of an operating system in regard to file management are:
- The creation and deletion of files.
- The creation and deletion of directions.
- The support of primitives for manipulating files and directions.
- The mapping of files onto secondary storage.
- The back up of files on stable storage media.
I/O System Management
I/O subsystem hides the peculiarities of specific hardware devices from the user. Only the device driver knows the peculiarities of the specific device to whom it is assigned.
Secondary-Storage Management
Generally speaking, systems have several levels of storage, including primary storage, secondary storage and cache storage. Instructions and data must be placed in primary storage or cache to be referenced by a running program. Because main memory is too small to accommodate all data and programs, and its data are lost when power is lost, the computer system must provide secondary storage to back up main memory. Secondary storage consists of tapes, disks, and other media designed to hold information that will eventually be accessed in primary storage (primary, secondary, cache) is ordinarily divided into bytes or words consisting of a fixed number of bytes. Each location in storage has an address; the set of all addresses available to a program is called an address space.
The three major activities of an operating system in regard to secondary storage management are:
- Managing the free space available on the secondary-storage device.
- Allocation of storage space when new files have to be written.
- Scheduling the requests for memory access.
Networking
A distributed systems is a collection of processors that do not share memory, peripheral devices, or a clock. The processors communicate with one another through communication lines called network. The communication-network design must consider routing and connection strategies, and the problems of contention and security.
Protection System
If a computer systems has multiple users and allows the concurrent execution of multiple processes, then the various processes must be protected from one another's activities. Protection refers to mechanism for controlling the access of programs, processes, or users to the resources defined by a computer systems.
Command Interpreter System
A command interpreter is an interface of the operating system with the user. The user gives commands with are executed by operating system (usually by turning them into system calls). The main function of a command interpreter is to get and execute the next user specified command. Command-Interpreter is usually not part of the kernel, since multiple command interpreters (shell, in UNIX terminology) may be support by an operating system, and they do not really need to run in kernel mode. There are two main advantages to separating the command interpreter from the kernel.
- If we want to change the way the command interpreter looks, i.e., I want to change the interface of command interpreter, I am able to do that if the command interpreter is separate from the kernel. I cannot change the code of the kernel so I cannot modify the interface.
- If the command interpreter is a part of the kernel it is possible for a malicious process to gain access to certain part of the kernel that it showed not have to avoid this ugly scenario it is advantageous to have the command interpreter separate from kernel.
A Process is a program in execution. It is an active entity.
In process management, the OS must allocate resources to processes, enable processes to share and exchange information, protect the resources of each process from other processes and enable synchronization among processes. To meet these requirements, the OS must maintain a data structure for each process, which describes the state and resource ownership of that process, and which enables the OS to exert control over each process.
The operating system manages many kinds of activities ranging from user programs to system programs like printer spooler, name servers, file server etc. Each of these activities is encapsulated in a process. A process includes the complete execution context (code, data, PC, registers, OS resources in use etc.).
It is important to note that a process is not a program. A process is only ONE instant of a program in execution. There are many processes can be running the same program. The five major activities of an operating system in regard to process management are
- Creation and deletion of user and system processes.
- Suspension and resumption of processes.
- A mechanism for process synchronization.
- A mechanism for process communication.
- A mechanism for deadlock handling.
 |
| Process States |
Process Control Block:
A process in an operating system is represented by a data structure known as a process control block (PCB) or process descriptor. The PCB contains important information about the specific process including- Process State (The current state of the process i.e., whether it is ready, running, waiting, or whatever.)
- Process ID (Unique identification of the process in order to track "which is which" information.)
- Parent Process ID (A pointer to parent process.)
- Child Process ID (Similarly, a pointer to child process (if it exists).)
- Process Priority (The priority of process (a part of CPU scheduling information).)
- Pointers to locate memory of processes.
- A register save area.
- The processor it is running on.
Context Switch:
It is the action performed by the operating system to remove a process from the run state and replace it with another.
Reasons for Process Termination:
There are many reasons for process termination:
- Batch job issues halt instruction
- User logs off
- Process executes a service request to terminate
- Error and fault conditions
- Normal completion
- Time limit exceeded
- Memory unavailable
- Bounds violation; for example: attempted access of (non-existent) 11th element of a 10-element array
- Protection error; for example: attempted write to read-only file
- Arithmetic error; for example: attempted division by zero
- Time overrun; for example: process waited longer than a specified maximum for an event
- I/O failure
- Invalid instruction; for example: when a process tries to execute data (text)
- Privileged instruction
- Data misuse
- Operating system intervention; for example: to resolve a deadlock
- Parent terminates so child processes terminate (cascading termination)
- Parent request
CPU Scheduling
Scheduler
The part of an operating system which assigns resources to processes, tasks, or threads.
The operating system component which transitions a process to the running state.
The operating system act of interrupting a running task, removing it from the run state, and placing it in the ready state.
Having the capability of preempting running tasks.
Not having the capability of preempting running tasks. Nonpreemptive operating systems allow a task to remain in the run state until it voluntarily blocks itself (usually by an I/O request) or completes.
Scheduling Objectives:
- Maximize throughput
- Maximize system utilization
- Minimize system overhead
- Minimize average response time
- Minimize maximum response time
- Minimize average turnaround time
- Minimize maximum turnaround time
- Maximize "fairness"
- Minimze failures
- Maximize reliability
- Eliminate indefinite postponement
- Maximize predictability (consistency)
Long-term Scheduling:
The long-term, or admission scheduler, decides which jobs or processes are to be admitted to the ready queue (in the Main Memory). The long term scheduler is also referred to as the high-level scheduler. It determines which programs are admitted to the system for execution and when, and which ones should be exited.
Medium-term Scheduling:
The medium-term scheduler temporarily removes processes from main memory and places them on secondary memory (such as a disk drive) or vice versa. This is commonly referred to as "swapping out" or "swapping in". It determines when processes are to be suspended and resumed.
Short-term Scheduling:
The short-term scheduler (also known as the CPU scheduler) decides which of the ready, in-memory processes are to be executed (allocated a CPU) next following a clock interrupt, an IO interrupt, an operating system call or another form of signal. Thus the short-term scheduler makes scheduling decisions much more frequently than the long-term or mid-term schedulers. It determines which of the ready processes can have CPU resources, and for how long.
Scheduling Algorithms:
FCFS
SJF
Round-Robin
Priority-based
Multi-level queue scheduling
--------------------------------------------------------------------------------------------
Deadlock
Deadlock refers to a specific condition when two or more processes are each waiting for the other to release a resource, or more than two processes are waiting for resources in a circular chain.Deadlock Characterization
Deadlock can arise if four conditions hold simultaneously:
• Mutual exclusion: a resource cannot be used by more than one process at a time
• Hold and wait: a process holding at least one resource is waiting to acquire additional resources held by other processes
• No preemption: a resource can be released only voluntarily by the process holding it, after that process has completed its task
• Circular wait: there exists a set {P0, P1, …, Pn, P0} of waiting processes such that
– P0 is waiting for a resource that is held by P1,
– P1 is waiting for a resource that is held by P2,
– …,
– Pn–1 is waiting for a resource that is held by Pn,
– and Pn is waiting for a resource that is held by P0.
RESOURCE ALLOCATION GRAPH
Deadlock can be described through a resource allocation graph.
Resource Allocation Graph consists of:
rectangles (for resources)
circles (for processes)
arrows
A directed edge (arrow) from a processes to a resource, Pi->R j, implies that Pi has requested Rj.
A directed edge (arrow) from a resource to a process, Rj->Pi, implies that Rj has been allocated by Pi.
If the graph has no cycles, deadlock cannot exist. If the graph has a cycle, deadlock may exist.
Example of Resource Allocation Graph shows no deadlock.

Example of Resource Allocation Graph With A Cycle But No Deadlock

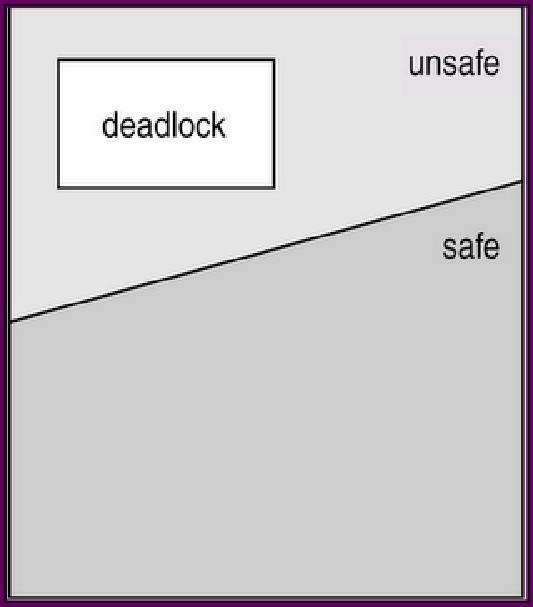
Safe, Unsafe , Deadlock State
Methods for Handling Deadlocks
• Ignore the problem and pretend that deadlocks would never occur
• Ensure that the system will never enter a deadlock state (prevention or avoidance)
• Allow the system to enter a deadlock state and then detect/recover
Deadlock Recovery
Recovery from Deadlock
• Recovery through preemption
– take a resource from some other process
– depends on nature of the resource
• Recovery through rollback
– checkpoint a process state periodically
– rollback a process to its checkpoint state if it is found deadlocked
• Recovery through killing processes
– kill one or more of the processes in the deadlock cycle
– the other processes get its resources
• In which order should we choose process to kill?
-----------------------------------------------------------------------------------------
Memory Management
The memory management is a major component of an operating system. A memory is central to a computer's operation. Main memory is a large array of words or bytes, size ranging from thousands of bytes to millions of bytes shared by input, output devices and the CPU(Central Processing Unit). The disk is the secondary memory. The Operating System activities with respect to the Memory Management are the following:
> Allocation and deallocation of memory space as and when needed.
> When space is available, which process has to be loaded into that space.
> Keeping track of which part of memory is used and by which process.
Logical Address and Physical Address
Address generated by the CPU is called Logical Address. Physical Address is the actual address as seen by the memory unit. Logical address is also called as Virtual address. Logical and physical addresses do not differ in compile and load time. They differ in execution time.
The set of all logical addresses generated by a user program is called as Logical Address Space. The set of all physical addresses corresponding to these logical addresses is called as Physical Address Space.
Address Binding: Address binding, also called mapping, is the process of converting one address space to another.
Memory Management Unit: This is a hardware device used for mapping the logical address space to the physical address space.
Dynamic Loading: Dynamic Loading is a process which offers better memory space management. Only the main program is loaded into memory and executed. The routines like functions and procedures are kept in the disk in relocatable format and they are loaded into the memory only when called. When the main program loaded into the memory is executed, one routine calls another. If the called routine is not loaded then the relocatable linking loader is called to load the module and the program's address tables are updated. Now the control is passed to the newly loaded routine. The advantages of Dynamic Loading is that an unused routine is never loaded. It is particularly useful when large code is needed to handle error routines that are less frequent.
Dynamic Linking: The system language libraries are loaded like other object modules. In static linking all programs need a copy of the language library routines. This wastes the disk space and the space of main memory. Dynamic linking is like dynamic loading. A piece of code usually called the stub, indicates the location of memory resident library routines or to load if not in memory. Here, only one copy of the library code is required.
Virtual Memory: It is the memory simulated in software by swapping with a disk file.Page: A fixed size block of contiguous memory addresses in a virtual address space which is managed as a unit.
Page Frame: A fixed size block of contiguous memory addresses in a real address space which is managed as a unit.
Segment: A variable size block of contiguous memory addresses in a virtual address space which is managed as a unit.
Page Fault: An interrupt generated when a program references a page that is not currently resident.
Demand Paging: A paging policy which reads in a page only when it is referenced.
Contiguous Memory Allocation
Contiguous Memory: The largest chuck of available memory that is not fragmented.Memory allocation: When a program asks for memory and gets it.
Contiguous memory allocation is one of the simplest ways of allocating main memory to the processes.
In contiguous memory allocation each process is contained in a single contiguous section of memory. In this method it possible to allocate memory space for a new processes if a contiguous memory space of the required size is available in the main memory. Otherwise the processes are made to wait until contiguous space of the required size is available.
For example, if 2 processes of size 5MB & 8 MB are allocated space in the main memory. The main memory size is say 32MB out of which the first 10MB is allocated to OS, leaving 22MB memory for user processes. Out of this processes A and B together will take 13MB leaving 9MB free. Now if a third process C of size 10MB is to be run then it has to wait until so much contiguous space is available. When process A complete,
the memory space (from 10MB to 15MB) is freed and a total of 14MB free space is available in memory. However, memory can not be allocated to Process C, as the maximum available contiguous free space is only 9MB! So C can run only after B is also completed.
Internal fragmentation:
When memory is free internally, that is inside a process but it cannot be used, we call that fragment as internal fragment. For example say a hole of size 18464 bytes is available. Let the size of the process be 18462. If the hole is allocated to this process, then two bytes are left which is not used. These two bytes which cannot be used forms the internal fragmentation. The worst part of it is that the overhead to maintain these two bytes is more than two bytes.
External fragmentation:
When the total memory space that is got by adding the scattered holes is sufficient to satisfy a request but it is not available contiguously, then this type of fragmentation is called external fragmentation.
The solution to this kind of external fragmentation is compaction. ( Compaction is a method by which all free memory that are scattered are placed together in one large memory block. )
The problem of fragmentation is solved in non contiguous memory allocation.
Paging and Segmentation are the popular non contiguous memory schemes. Here the memory available need not be contiguous. The whole memory is broken into pages or segments as the case may be.
( For more info. visit: http://www.indiastudychannel.com/resources/136406-Memory-Management-Operating-Systems.aspx )
------------------------------------------------------------------------------------------
Paging
Virtual address space is divided into several pieces (or blocks) of equal length called pages. Likewise the physical memory is divided into equal sized frames.Address generated by CPU is divided into
PAGE TABLE: For each of the processes there is a page table which contains the mapping information of logical pages to physical frames. The ith entry in a page table stores, the validity of the entry in the page table, the physical frame to which logical page i is mapped to, protection info on the the logical page, and whether or not page has been modified by the process. Note that the page table itself is stored in the main memory.Implementation of Page Table
· Page table is kept in main memory
· Page-table base register (PTBR) points to the page table
· Page-table length register (PRLR) indicates size of the page table
· In this scheme every data/instruction access requires two memory accesses. One for the page table and one for the data/instruction.
· Address translation (p, d)
· If p is in associative register, get frame # out
· Otherwise get frame # from page table in memory
 |
| ( Click on the diagram for larger view ) |
Advantages of paging
|
Swapping:
Swapping refers to replacing pages or segments of data in memory.
Swapping is a useful technique that enables a computer to execute programs and manipulate data files larger than main memory. The operating system copies as much data as possible into main memory, and leaves the rest on the disk. When the operating system needs data from the disk, it exchanges a portion of data (called a page or segment ) in main memory with a portion of data on the disk.
Swapping is a simple memory/process management technique used by the operating system(os) to increase the utilization of the processor by moving some blocked process from the main memory to the secondary memory(hard disk);thus forming a queue of temporarily suspended process and the execution continues with the newly arrived process.
Swapping of a process takes place to create (enough) main memory space for a currently running process.
Page Replacement Algorithms:
FIFO
LRU
Optimal Page Replacement
File Management
File: A file of a collection of data that normally is stored on a secondary storage device such as a hard disk or floppy disk.
A file has a name. A file name consists of:
1. drive name2. directory name(s)
3. file name
4. extension
Windows Filenames can be up to 255 characters long and are not case-sensitive.
File name and extension are separated by a dot. The directories are separated by slashes (UNIX) or back slashes (Windows, DOS).
Example: C:
/usr/home/data/syllabus.docFile system is the software which empowers users and applications to organize and manage their files. The organization and management of files may involve access, updates and several other file operations.
File system resides on secondary storage (disks).
The file manager handles all files on secondary storage media. To perform these tasks, file management must:
|
DIRECTORY
It is a group with related files in it.
A DIRECTORY is a division of a drive into which you put files or further folders (which are then called subdirectories).
A folder (directory) could be placed within another folder.All modern OSs support such a hierarchical file organization. In hierarchical file organization, a directory may contain subdirectories and further subdirectories.
Within a directory each file must have a distinct name.
Folders contain files; files cannot contain folders.Operations performed on a file: An operating system must provide a number of operations associated with files so that users can safely store and retrieve data.
Typical operations are
In addition, operations on single data elements within a file are supported byCreate :
ReadCreate
Write
Seek
o Constructs a file descriptor on disk to represent the newly created file
o Adds an entry to the directory to associate name with that file descriptor
o Allocates disk space for the file
o Adds disk location to file descriptor
Delete
Deletes the file’s file descriptor from the disk, and removes it from the directory
File Control Block (FCB):
It is also known as file descriptor.
File control blocks (FCB) are data structures that hold information about a file. When an operating system needs to access a file, it creates an associated file control block to manage the file.It is a storage structure consisting of information about a file.
Ø The length of the data contained in a file may be stored as the number of blocks allocated for the file or as a byte count.
Ø The time that the file was last modified may be stored as the file's timestamp. File systems might store the file creation time, the time it was last accessed, the time the file's meta-data was changed, or the time the file was last backed up.
Ø Other information can include the file's device type (e.g. block, character, socket, subdirectory, etc.), its owner user ID and group ID, and its access permission settings (e.g. whether the file is read-only, executable, etc.).
Ø Some file systems provide for user defined attributes such as the author of the document, the character encoding of a document or the size of an image.
File control blocks include the following parts:
· Filename
· Location of file on secondary storage
· File size (or length of file)
· Date and time or creation or last access
· File Permissions
· File Owner
Filename |
Location of file on secondary storage |
File dates (create, access, write) |
File Owner, Group |
File Size |
File Permissions |
FILE CONTROL BLOCK
Naming Files: Each operating system uses a specific convention or practice for naming files.
MS-DOS Uses eight character file names, a dot, then a three-character extension that denotes the type of file. Filenames are not case-sensitive.
UNIX Filenames can be up to 254 characters long and are case-sensitive.
Windows Filenames can be up to 255 characters long and are not case-sensitive.
File Types: File types refer to classifying the content of the file, such as a program, text file, executable program or data file.
In Windows operating systems, the file type is derived from the filename extension. Typical file types and their extensions are:
| File Extension | File Type |
| .bas | basic source program |
| .c | c source program |
| .dll | system library |
| .doc | Word document |
| .exe | executable program |
| .txt | text file |
Keeping track of files: The hard disk is comprised of a large number of sequentially numbered sectors. As files are created, free sectors are allocated to hold the file contents and marked as allocated.
To keep track of the sectors and whether they are allocated or free, and to which file they belong, the operating system maintains a number of tables.
Root File System:
When an OS is installed initially, it creates a root file system.
The OS not only ensures, but also specifies how the system and user files shall be distributed for space allocation on the disk storage. Almost always the root file system has a directory tree structure.
The root file system has several subdirectories. OS creates disk partitions to allocate files for specific usages. A certain disk partition may have system files and some others may have other user files or utilities.
One major advantage of the root file system is that the system knows exactly where to look for some specific routine.
A root file system entry looks like:
Name of file
Beginning cluster number
Length of file in bytes
Type of file
Creation date and last modified right
File permissions (an access control list)
Clusters: To make things a little simpler than managing a large number of sectors, the operating system groups sectors together into a minimum allocation unit called a cluster. When a request to create a file occurs, the operating system allocates a cluster at a time until the all the data is stored.
ALLOCATION METHODS |
An allocation method refers to how disk blocks are allocated for files.
Contiguous Allocation
With contiguous file allocation, a single set of blocks is allocated to a file at the time of file creation. Each file is stored contiguously, one sector after another.
OS keeps an ordered list of free blocks.
· Allocates contiguous groups of blocks when it creates a file
· File descriptor must store start block and length of file.
In contiguous file allocation method, each file occupies a set of contiguous blocks on the disk.
ü Simple – only starting location (block #) and length (number of blocks) are required.
ü Random access.
ü Wasteful of space (dynamic storage-allocation problem).
ü Files cannot grow
Contiguous allocation is widely used on CD-ROMs. Here all the file sizes are known in advance and will never change during subsequent use of the CD-ROM file system. Accessing a file that has been allocated contiguously is easy.
+ For sequential access, the file system remembers the disk address of the last block referenced and, when necessary, reads the next block.
+ For direct access to block
External fragmentation exists whenever free space is broken into chunks.
Another problem with contiguous allocation is determining how much space is needed for a file.
Advantages:
· The retrieval of information is very fast.
· FAT only has to have a single entry for each file, indicating the name, the start sector, and the length. · It is easy to get a single block because its address can simply be calculated: If a file starts at sector c, and the nth block is wanted, the location on secondary storage is simply c+n. |
The disadvantages are that:
<> It may be difficult (if not impossible) to find a sufficiently large set of contiguous blocks. From time to time it will be necessary to perform compaction.
<> In most cases it is not possible to know, in advance, the size of a file being created.
<> There are some files that already exist and it is not easy to find contiguous regions. For instance, even though there may be enough space in the disk, yet it may not be possible to find a single large enough chunk to accommodate an incoming file.
<> Users' needs evolve and a file during its lifetime undergoes changes. Contiguous blocks leave no room for such changes. That is because there may be already allocated files occupying the contiguous space.Linked/chained Allocation
OS keeps an ordered list of free blocks.ü File descriptor stores pointer to first block
ü Each block stores pointer to next block
Each file is a linked list of disk blocks: blocks may be scattered anywhere on the disk.
· Simple – need only starting address· Free-space management system – no waste of space
· No random access
· Mapping
Chained list allocation does not require size information in advance. Also, it is a dynamic allocation method.
Linked allocation solves the external-fragmentation and size-declaration problems of contiguous allocation.
Linked allocation solves all problems of contiguous allocation. With linked allocation, each file is a linked list of disk blocks; - The disk blocks may be scattered anywhere on the disk.
- The directory contains a pointer to the first and last blocks of the file.
- To create a new file, we simply create a new entry in the directory. The pointer is initialized to nil (the end-of-list pointer value) to signify an empty file. The size field is also set to O.
- A write to the file causes the free-space management system to find a free block, and this new block is written to and is linked to the end of the file.
- To read a file, we simply read blocks by following the pointers from block to block.
- There is no external fragmentation with linked allocation, and any free block on the free-space list can be used to satisfy a request. No space is lost to disk fragmentation (except for internal fragmentation in the last block).
- The size of a file need not be declared when that file is created. A file can continue to grow as long as free blocks are available.
Disadvantages:
# Maintenance of chained links may not be easy.# In the absence of a FAT, linked allocation cannot support efficient direct access, since the pointers to the blocks are scattered with the blocks themselves all over the disk and must be retrieved in order.
# Another problem of linked allocation is reliability. The files are linked together by pointers scattered all over the disk, and consider what would happen if a pointer were lost or damaged. A bug in the OS software or a disk hardware failure might result in picking up the wrong pointer.
# Another disadvantage is the space required for the pointers. If a pointer requires 4 bytes out of a 512-byte block, then 0.78 percent of the disk is being used for pointers, rather than for information.
INDEXed Allocation
In indexed allocation, we maintain an index table for each file in its very first block. Thus it is possible to obtain the address information for each of the blocks with only one level of indirection, i.e. from the index. This has the advantage that there is a direct access to every block of the file. This means we truly operate in the direct access mode at the block level.
OS keeps a list of free blocks.OS allocates an array (called the index block) to hold pointers to all the blocks used by the file
· Allocates blocks only on demand· File descriptor points to this array.
· Brings all pointers together into the index block.
ü Need index table
ü Random accessü Dynamic access without external fragmentation, but have overhead of index block
- Each file has its own index block, which is an array of disk-block addresses.
- The
- Indexed allocation supports direct access, without suffering from external fragmentation, because any free block on the disk can satisfy a request for more space.
- Indexed allocation does suffer from wasted space
Disadvantage: In terms of storage the overhead of storing the indices is more than the overhead of storing the links in the chained list arrangements.
The disadvantage is that for each file an additional sector is needed. Even a very small file always occupies at least two blocks, where the data would easy fit in one. So some of the secondary storage space is wasted.=============================================================
Free Space Management
· Since disk space is limited, we need to reuse the space from deleted files for new files, if possible. · To keep track of free disk space, the system maintains a free-space list. The free-space list records all free disk blocks.
· To create a file, we search the free-space list for the required amount of space and allocate that space to the new file.
· When a file is deleted, its disk space is added to the free-space list.
· Bit Vector
· Linked List
· Grouping
· Counting
Bit Vector
· Frequently, the free-space list is implemented as a bit map or bit vector. · Each block is represented by 1 bit.
· If the block is free, the bit is 1;
· If the block is allocated, the bit is O.
· For example, consider a disk where blocks 2, 3, 4, 5, 8, 9, 10, 11, 12, 13, 17, 18,25,26, and 27 are free and the rest of the blocks are allocated. · The free-space bit map would be
001111001111110001100000011100000 ...
· The main advantage of this approach is its relative simplicity and its efficiency in finding the first free block or consecutive free blocks on the disk. · Unfortunately, bit vectors are inefficient unless the entire vector is kept in main memory (and is written to disk occasionally for recovery needs).
· Keeping it in main memory is possible for smaller disks but not necessarily for larger ones.
Linked List
· Another approach to free-space management is to link together all the free disk blocks, keeping a pointer to the first free block in a special location on the disk and caching it in memory. · This first block contains a pointer to the next free disk block, and so on.
For example, consider a disk where blocks 2, 3, 4, 5, 8, 9, 10, 11, 12, 13, 17, 18,25,26, and 27 are free and the rest of the blocks are allocated.
· We would keep a pointer to block 2 as the first free block. · Block 2 would contain a pointer to block 3,
which would point to block 4,
which would point to block 5,
which would point to block 8, and so on
However, this scheme is not efficient; to traverse the list, we must read each block, which requires substantial I/O time. Fortunately, traversing the free list is not a frequent action. Usually, the OS simply needs a free block so that it can allocate that block to a file, so the first block in the free list is used.
It is not surprising that the bitmap requires less space (60000 blocks), since it uses 1 bit per block, versus 32 bits in the linked list model. Only if the disk is nearly full (i.e., has few free blocks) will the linked list scheme require fewer blocks than the bitmap.
Grouping
· A modification of the free-list approach is to store the addresses of free blocks in the first free block. · The addresses of free-blocks are stored in the first free-block.
· The first of these blocks are actually free. The last block contains the addresses of another free blocks, and so on.
· The addresses of a large number of free blocks can now be found quickly, unlike the situation when the standard linked-list approach is used.
Counting
· Another approach is to take advantage of the fact that, generally, several contiguous blocks may be allocated or freed simultaneously, particularly when space is allocated with the contiguous-allocation algorithm or through clustering. · Thus, rather than keeping a list of free disk addresses, we can keep the address of the first free block and the number of free contiguous blocks that follow the first block.
· Each entry in the free-space list then consists of a disk address and a count.
· Although each entry requires more space than would a simple disk address, the overall list will be shorter, as long as the count is generally greater than 1.
====================================================================
File Systems supported by Windows OS :
The Windows operating system supports the following file systems.
| FAT | The MS-DOS operating system introduced the File Allocation Table system of keeping track of file entries and free clusters. Filenames where restricted to eight characters with an addition three characters signifying the file type. The FAT tables were stored at the beginning of the storage space. |
| FAT32 | An updated version of the FAT system designed for Windows 98. It supports file compression and long filenames. |
| NTFS | Windows NT introduced the NT File System, designed to be more efficient at handling files than the FAT system. It spreads file tables throughout the disk, beginning at the center of the storage space. It supports file compression and long filenames. |
======================================================================
=====================Some Other Definitions================================
======================================================================
System Call:
A System call is a mechanism used by an application for requesting a service from the operating system.The invocation of an operating system routine. Operating systems contain sets of routines for performing various low-level operations. For example, all operating systems have a routine for creating a directory. If you want to execute an operating system routine from a program, you must make a system call.
System calls provide the interface between a process and the operating system.
Many of the modern OSes have hundreds of system calls. For example Linux has 319 differenct system calls.
The services provided by operating system can be used by an application with the help of system calls.
Example: open, close, read, write, kill, wait etc.
=================================================================
Simple Batch and Multiprogramming Systems:
| SIMPLE BATCH SYSTEM | MULTIPROGRAMMING BATCH SYSTEM |
| It consists of a sequence of processes and control is transfered automatically from process to process. | In this, when one one process waits for the completion of an I/O operation, another process is executed. |
| It saves setup time for processes. | Setup time for processes is increased due to scheduling. |
| It leads to less utilization of CPU and other resources. | It increases resources and CPU utilization. |
| It increases the waiting time for processes. | It reduces the waiting time for processes. |
| It does not require scheduling algorithm. | It requires scheduling algorithm. |
Memory Layout (Simple Batch System)
| OPERATING SYSTEM |
| User Program |
Memory Layout (Multiprogramming Batch System)
| OPERATING SYSTEM |
| User Program 1 |
| User Program 2 |
| User Program 3 |
| . . . |
| User Program n |
(
For more information on OS concepts visit:
http://www.personal.kent.edu/~rmuhamma/OpSystems/os.html
http://u.cs.biu.ac.il/~wiseman/os/os/
http://www.eecg.toronto.edu/~jacobsen/os/2007s/memory.pdf
http://uva.ulb.ac.be/cit_courseware/opsys/ostart.htm
http://en.kioskea.net/contents/systemes/sysintro.php3
)